A tour of the data engineering landscape
Data Engineering (DE) is an interesting field of study particulary to me since it touches on both hardware and networking stacks as well as traditional software development with strong emphasis on data structures and algorithms. And although in practice, much of the tooling is plug and play, I wanted to give tour of the DE landscape and provide a motivation for why and how some of these tools are used. Coincidentally since much of this space is driven by projects which share the Apache licence, this writeup can also be seen as an overview of the Apache ecosystem.
Data platforms
Datawarehouse
We begin our journey with a traditional relational database. A relational database organizes data using a B- tree data structure. A data structure as simply a way of organizing data similarly to how a dictionary organizes words and their corresponding definitions by alphabetical order. In the case of a dictionary, when the user wants to find the definition of a specific word they will not turn to the start of the dictionary and begin scanning every page until they arrive at the word, instead they use the first letter of the desired word to jump to the corresponding section of the dictionary. They will continue to do this process for every subsequent letter of the word until the finally arrive, skipping a large portion of effort scanning the whole dictionary. When a new word is added to a dictionary, processing power is required to find the right location of the word so that subsequent searches remain efficient. Databases behave with the same philosophy, process and sort records on insert and searching for them later will be efficient. However instead of alphabetical order, databases use B-tree, a type of tree data structure.
To understand this tree strucutre roughly, I will first look at the simplest form of a tree, the binary tree. Data, such as the records in a table, is represented as nodes. Nodes can be parent nodes, which point to two other children nodes left or right of itself, or is a leaf node with no children. The only node which does not have a parent is the root node. When a new node needs to be inserted to an existing tree, the B-tree insertion algorithm starts the root node and decides if it should be to the left or right of it depending on a criteria referred to as the index. The index informs us on how the tree is constuctured and its resulting performance. Hence the index must be chosen depending on the business case of the data. The figure below hopes to illustrate this visually. Note, relational databases don’t use binary trees, but B-trees which are more sophisticated by the philosphy of a organized tree making data quicker to access remains the same. The below animation hopes to illustrate this process for a tree containing simple toy product sales data. The tree uses the price field as an index but the tree could have just as easily used the quantity field or product name as an index resulting in a different tree structure.
Thus we see datawarehouses embody the following philosohy: “slower insert now (due to processing where in the tree the node goes and ensuring correct structure) but fast access later”
It is also somewhat evident, relational databases cannot scale horizontally. Put another way, I cannot simply add another separate server running the same database software with the purposes of extending disk space or compute power since different machine are storing different trees. It is impractical to try coordinate data between trees especially given later architecture advancements. In short, datawarehousing is limited to vertical scaling meaning the only way to upgrade the storage or performance of the database is to simply upgrade the storage and hardware of the server running the database software.
Data Lake
In contrast to the datawarehouse philosophy and aided by the growing amount of data collected by modern information systems a new philosophy arose: “Store now, process later.” Industry is continuely finding new ways of using the data generated by users for purposes not originally intended (the underlying theme in data science). Recent examples is companies organizing pdfs, emails, video, audio, image data etc. for AI/LLM training. This type of data naturally cannot be simply organized into records into a tree. Instead this type of data is considered unstructured.
We cannot talk about the rise of unstructured data without also addressing the challenge of distributed storage to manage all this new data. Thus, the philosphy of data lakes is further enabled by the adoption of object storage. Allow me to explain how object storage differs from how we traditionally store data on our machines. All computers have some sort of persistent storage such as a spinning hard disk drive (HDD), or solid state drive (SSD). The smallest section of data one can write to a drive is a block and is typically 4096 bytes. Users however, don’t keep track over which individual blocks they would like to read/write to. They instead think about the files and directories they are creating. It is clear to see therefore, additional metadata is required to keep track which blocks a files and directories belong to. This is the job of the filesystem. It is the data structure sitting in cordon off sections of the disk with information of which blocks are used for which files and directories. The elements of this filesystem data structure are referred to as inodes (index nodes). Inodes, like a B-tree, form a data structure which is used by the filesystem to keep track of files and directories and make searching for an updating these inodes easier.
However, returning to the industry movement of storing large amounts of unstrucutured data, we come across a limitation of filesystems. You see, filesystems as with B-trees have a limitation when it comes to scaling horizontally. Put another way, it is difficult to keep a filesystem consistant if it is distributed over multiple machines. For instance when a file is added to a distributed filesystem, the other machines in distributed system must also be aware of it as not to overwrite its data later. Although difficult, distributed filesystems do exist such as Apache Hadoop. However, and in keeping with the philosophy of “store now quickly; process later” for data lakes, industry realized much of the functionality of a file system can be forfeited for the sake of distributed computing. Thus we arrive at object storage, which is a simple flat key-value pair data structure. Data is accessed by looking up its corresponding key which itself maps to physical disk space. Thus making it easy to add and access data even over a distributed storage solution. Examples of object storage include: Amazon’s S3 storage, Azure’s blob storage, Ceph and MinIO.
Data Lakehouse (Hybrid)
Naturally, the philosphy of “store now; process later” particularly with unstrucutred data meant data lakes can get quite messy. Scanning your data set for a particular file, would result in scanning the entire storage space all over again (functionality lost since the filesystem was replaced with object storage). A “messy” data lake without a “data strategy or governance” is sometimes referred to as a data swamp.
Thus to keep data lakes organized, a hybrid approach was adapted to reintroduce some of the benefits of a filesystem. This hybrid adoption is being led by the Apache Iceberg project. The Iceberg project is simply a table format for organizing files in object storage. It can be thought of as not only a table schema for storing information about files in a data lake but also defines a process for how data is inserted / updated. Allowing for clear oversight over how the storage is evolving at various points in time and searchable metadata about the files in object storage.
The workflow will be as follows:
- New unstructured data is introduced to the storage space.
- The data is processed using some sort of processing technique, such as machine learning, to produce metadata about the file often in the form of tag.
- The file is then stored on object storage and the metadata and location of the file is stored using Iceberg’s metadata tables.
- Thus data analysts in the future can simply search the Iceberg tables for desired data as opposed to scanning the entire storage space again.
Data streams
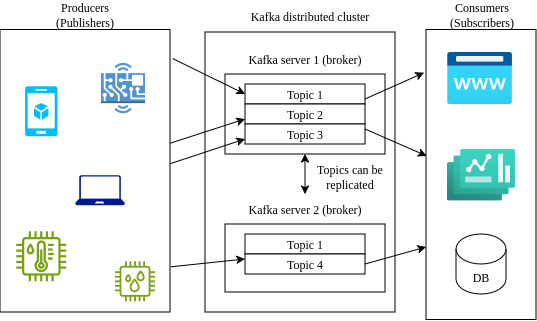
Data strems aren’t necessarily a architectural decision or best practice but simply highlight the way much of data is generated today. A few words about it will possibly explain why the water anaolgies are so strong in DE. Data is generated from multiple systems over multiple locations. This is especially evident with the rise of users having multiple personal machines and IoT devices. Apache Kafka, is a project for manageing data from distributed sources. It follows the event driven publisher / subscriber model (web developers would see something similar observables in Angular). The Kafka architecture includes producers which publish events to a server, and consumers which subscribe to the servers to receive data created by the producers. Kafka provides all the scaffolding and API code for devices running applications written with different programming languages in order to send messages over the TCP stack, ensuring data is consistent across the distributed system and functionality of organizing data streams into topics for selective subscription.
Speeding up analytical queries
It turns out in field of data science and analysis, searching for individual records (or nodes in a B-tree) is not the primary objective. Instead data analysts are interested with aggregated results of all or some columns of a dataset. Given how B trees make searching for nodes more efficient, there are various techniques such as reorganizing data to make analytical “aggregated” work more efficient.
Multidimensional cubes
In keeping with the philosophy of “process now for faster access later”, an immediate solution to speeding up aggregated workloads is to organize the data into dimensions and measures and then pre-calculate the usual aggregate values. Dimensions being the variables analysts typically filter on, and measures being the numerical variable for calculation. Using sales transactions as an example: date, product grouping and location may be dimensions and the revenue from the sale is the measure. Analysts can filter (“slice and dice”) the dimensions to get different perspectives of total revenue by date or product or location. Data organized this way is called a “multidimensional cube” and is a sparse matrix (matrix being the computer science matrix [i.e. a multidimensional array]) and is an easier data structure to traverse for data analysis than the B-trees we see in relational databases. An example of this is Microsoft’s SQL Server Analysis Services (SSAS).
Columnar Data Format
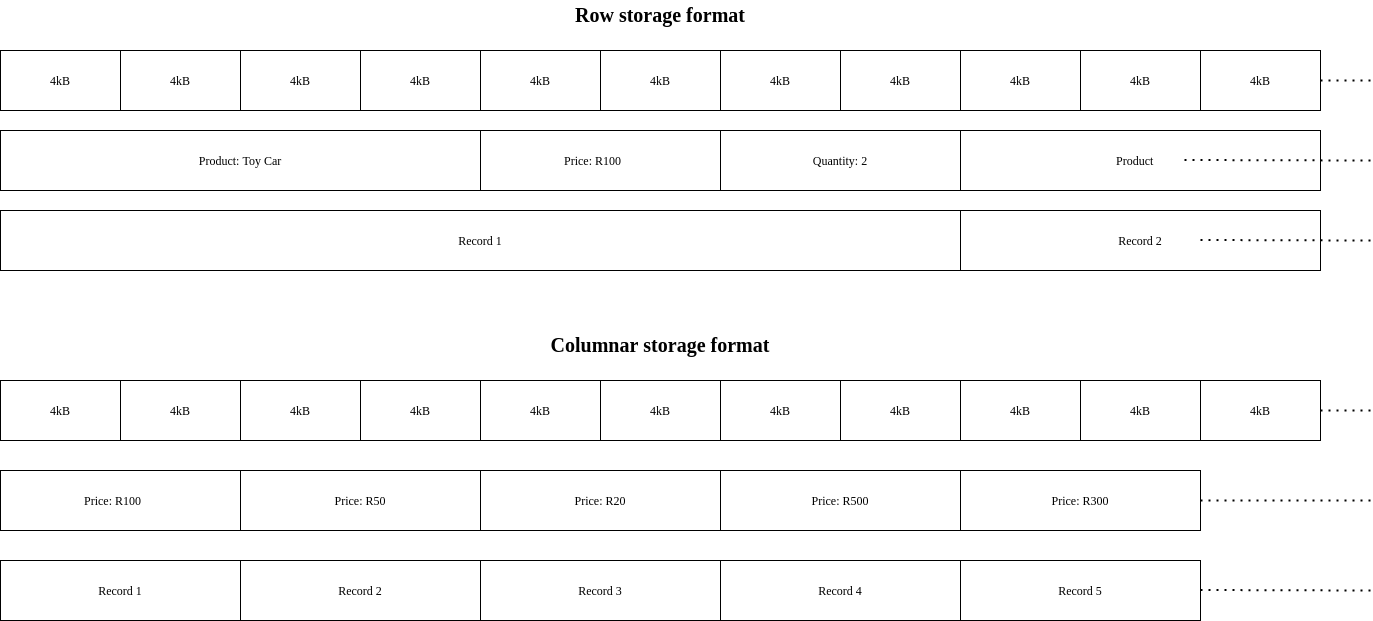
Another example, of “process now for faster access later”, is organizing data into columnar format and like the sparse matrices discussed with multidimensional cubes, this data structure facilitates more efficient analytical work. Columnar format is opposite to row format which we see in relational databases and plain csv files. For a CSV file, consider how the data is laid out on disk. Each record (row) is a line in the file and the bytes making up the line is laid out next to each other on the blocks of the disk. Once a record is complete the next record is stored in the subsequent block on disk. Thus is scan for all the values of a specific column, the machine must scan through all blocks for each record and store only a portion of the desired data in memory. Row storage also applies for relational databases even with the B-tree structure, since each node in the tree stores the entire record. The B-tree is essentially implemented with address pointers which make jumping around the disk faster for quicker access, but the entire row must still be scanned to pull the desired column value.
Thus and as the name suggests, columnar storage organizes the column values of the entire data set together in memory instead of keeping the columns of a single record together as a single unit. This means all the values of the first column are arranged sequentially on disk before the next column starts. Analytical workloads which are primarily interested in aggregated column values have faster access to those columns. The tradeoff, of course, this means finding all the column values for a single record would be terribly inefficient and is better suited for relational database structures.
Not only are data scans for analytical workloads more efficient with columnar formats, but columnar formats allow for vectorized processing which makes computation faster than traditional “single instruction single data” (SISD) seen with typical CPU workloads. Vectorized execution relies on CPU support and is a form of hardware acceleration and therefore will be discussed later there.
Apache Arrow
There are two main projects for columnar databse formats targeting whether data is being laid out in volatile (RAM) memory or persistent non-volatile memory. Apache Arrow lays out data in columnar format in volatile memory. It is the underlying tool for many popular data engineering projects such as Polars a Python dataframe library and DuckDB which acts as an interface to query Apache Arrow data.
Apache Parquet
Columnar formats are also useful when stored in non-volatile memory for two reasons. The first columnar storage also lends itself to better compression since grouping columns together also mean grouping similar values together making compression easier. Secondly, sotring as a columnar format prevents excessive re-processing when the processor needs to load data into RAM (volatile memory). Apache Parquet is an open source columnar based file format which in turn is stored on non-volatile memory like any other file. Apache Parquet also takes a page out of the preprocessed multidimensional cubes and includes common precalculated query metadata about the columns in the file for quick access. Query metadata includes max/min value, number of distinct and page offsets. This metadata is especially useful in analytical queries.
Apache Arrow works closely with Parquet files, since any job will require the data be transfered to RAM (volatile) memory in order for the processor to do work on it. Data is often loaded from Parquet files into memory using Arrow.
Other columnar OLAP
There are a few projects which implmented their own columnar engine before or instead of Apache Arrow. Examples include Snowflake and Apache Clickhouse. It is also worth mentioning timeseries databases, as Clickhouse if often used, are most likely columnar based given how the nature of timeseries data is almost always focused on analytical workloads.
Distributed Compute
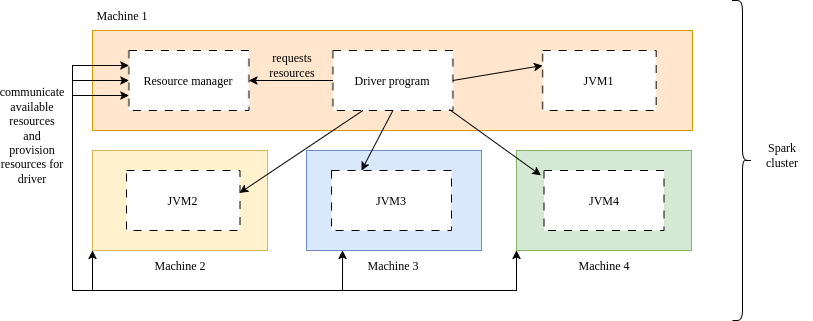
Much like how we can utilize multiple machines to grow storage space, similarly we can use multiple machines to speed up computation by distributing work over multiple machines to get it done faster. The de facto platform for distributed compute is the Apache Spark project. For a cluster of machines, the project spins up one or more (Java virtual machines) JVM on each machine. The JVM can simply be thought of as the running program which will eventually execute the operation. Individual Spark jobs are managed by a corresponding driver program. Before a Spark job can run, the driver must consult the resource manager for available resources and request available resources to be provisioned for the job. A resource manager could be Spark’s built in cluster manager, YARN or Kubernetes. The driver will then distribute data and code to the provisioned JVMs and collect the results. See the diagram below on how this architecture looks visually.
Hardware Acceleration
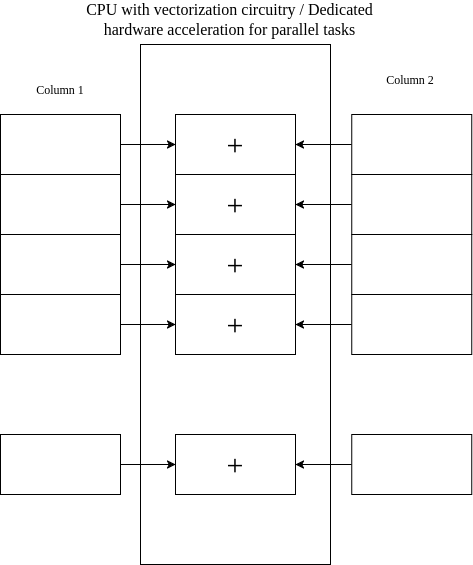
Fondationally any processing a machine does comes down to some sort of electrical circuitry performing the operation. CPUs on typical servers/desktops are general purpose circuits and only a small number of CPU cores can fit on a single chip. Hardware accelerators such as GP-GPUs and FPGAs implement a smaller specialized suset of functionality found on CPUs but create an order of magnitude more copies of the circuitry than the typical number of CPU cores. This means certain operations can be shared amoungst far more logic units speeding up operation speed than if a handful of CPU cores had to do everything. In fact, modern CPUs also include special vectorized circuitry for this exact purpose if wanting to avoid dedicated hardware accelerators. The illustration below hopes to highlight how in fact columnar storage lends itself to parallelized tasks where hardware acceleration is possible. We this this parallelization allow for single instruction multiple data (SIMD) as opposed to the single instruction single data (SISD) pipeline found in earlier traditional CPU workflows.
Automation
Data platforms are continuely on. Data is forever being created and added, and therefore platforms must forever be ingesting and processing it. Thus automation is a very important aspect to DE. Although there are a few tools, the philosophy is the same. Automation is are simply computer programmes which run on some sort of schedule. We rely on a computer to start and execute the job when the right time or conditions occur.
I believe the first versions of automations were shell scripts (e.g. BASH) that we automated using cron. Cron in essence runs a cron daemon (i.e. a program that continuoulsy runs in the background) checking to see if a task should run based on its defined schedule. Later projects like Apache Airflow, introduce a graphical interface and provides logging, task dependency management and error handling out of the box.
Typical automations include backup jobs, ETL pipelines, report generation, reminder emails and much more.
Closing thoughts
I hope this post highlighted the philosophy of processing on insert for faster access later versus cases where inserting now and processing later may be favoured. I also hope that everytime I mention processing one thinks about the underlying data structure of the data and that different data structures or layouts can yeild different results depending on the objective. Finally I hope the philosophy of speeding up computation by adding more parallel “workers” to the problem can lead to more efficient processing. These workers can be anything from more CPU cores, server machines to dedicated computation circuitry. In clsing I hope the above provides motivation that the best data platform isn’t the one that utilizes every tool listed above. Instead a data platform should start by deciding upon a philosophy to match the nature of data being worked with, then the right subset of tools will become evident.